One of my top favorite features of the Python programming language is generators. They are so useful, yet I don't encounter them often enough when reading open source code. In this post I hope to outline their simplest use case and hope to encourage any readers to use them more often.
This post assumes you know what a container and an iterator is. I've explained these concepts in a previous blog post. In a follow-up post, I elaborate on what can be achieved with thinking in streams a bit more.
Why? ¶
Why are iterators a good idea? Code using iterators can avoid intermediate variables, lead to shorter code, run lazily, consume less memory, run faster, are composable, and are more beautiful. In short: they are more elegant.
"The moment you've made something iterable, you've done something magic with your code. As soon as something's iterable, you can feed it to
list(),set(),sorted(),min(),max(),heapify(),sum(), ‥. Many of the tools in Python consume iterators."— Raymond Hettinger (source)
Recently, Clojure added transducers to the language, which is a concept pretty similar to generators in Python. (I highly recommend watching Rich Hickey's talk at Strange Loop 2014 where he introduces them.)
In the video, he talks about "pouring" one collection into another, which I think is a verb that very intuitively describes the nature of iterators in relationship to datastructures. I'm going to write about this idea in more detail in a future blog post.
Example ¶
Here's an example of a pattern commonly seen:
def get_lines(f):
result = []
for line in f:
if not line.startswith('#'):
result.append(line)
return result
lines = get_lines(f)
Now look at the equivalent thing as a generator:
def get_lines(f):
for line in f:
if not line.startswith('#'):
yield line
lines = list(get_lines(f))
The Benefits ¶
Not much of a difference at first sight, but the benefits are pretty substantial.
- No bookkeeping. You don't have to create an empty list, append to it, and return it. One more variable gone;
- Hardly consumes memory. No matter how large the input file is, the iterator version does not need to buffer the entire file in memory;
- Works with infinite streams. The iterator version still works if
fis an infinite stream (i.e. stdin); - Faster results. Results can be consumed immediately, not after the entire file is read;
- Speed. The iterator version runs faster than building a list the naive way;
- Composability. The caller gets to decide how it wants to use the result.
The last bullet is by far the most important one. Let's dig in.
Composability ¶
Composability is key here. Iterators are incredibly composable. In the
example, a list is built explicitly. What if the caller actually needs a set?
In practice, many people will either create a second, set-based version of the
same function, or simply wrap the call in a set(). Surely that works, but it
is a waste of resources. Imagine the large file again. First a list is built
from the entire file. Then it's passed to set() to build another collection
in memory. Then the original list is garbage collected.
With generators, the function just "emits" a stream of objects. The caller gets to decide into what collection those objects gets poured.
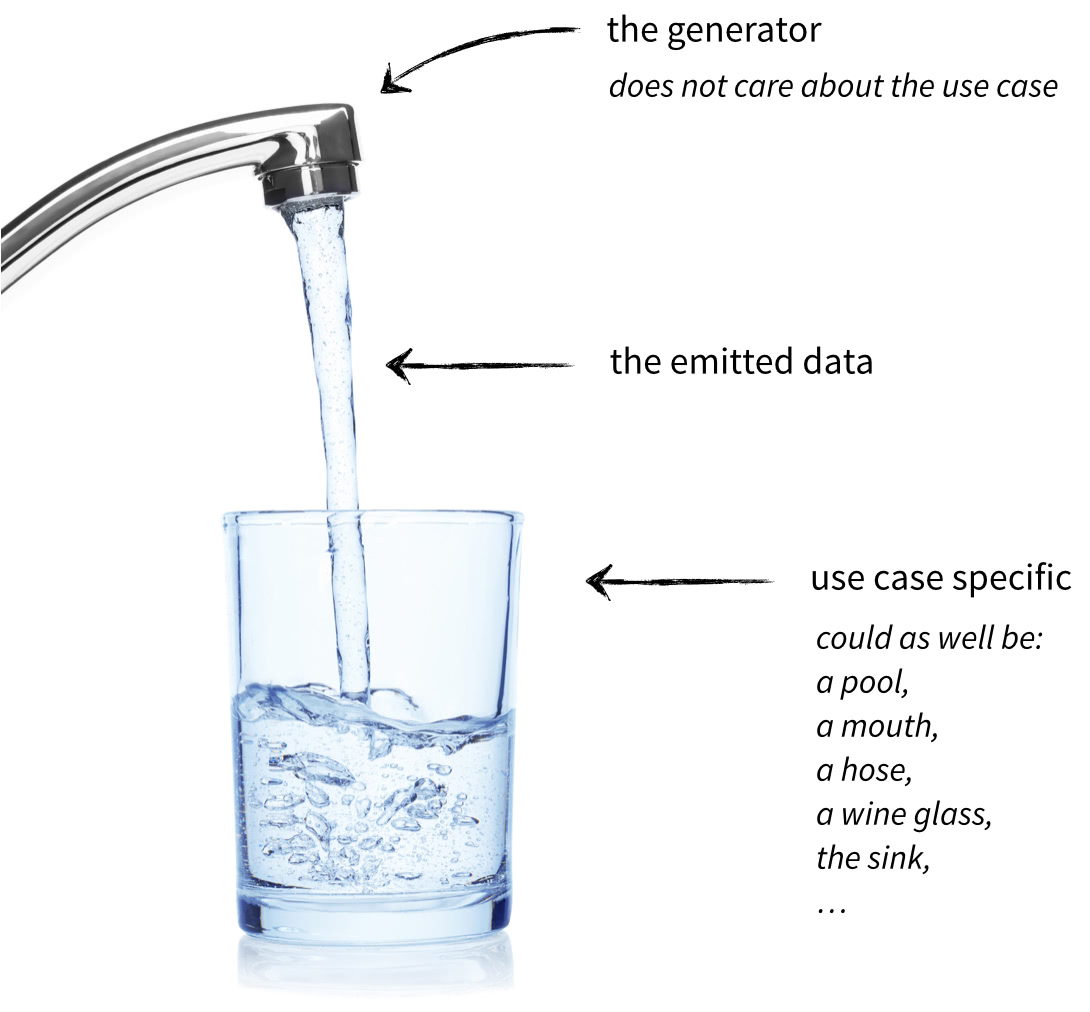
Want a set instead of a list?
uniq_lines = set(get_lines(f))
Want just the longest line from the file? The file will be read entirely, but at most two lines are kept in memory at all times:
longest_line = max(get_lines(f), key=len)
Want just the first 10 lines from the file? No more than 10 lines will be read from the file, no matter how large it is:
head = list(islice(get_lines(f), 0, 10))
Loop Like a Native ¶
Update: At PyCon 2013, Ned Batchelder gave a great talk that perfectly reflects what I tried to explain in this blog post. You can watch it here, I highly recommend it:
Summary ¶
Don't collect data in a result variable. You can almost always avoid them. You gain readability, speed, a smaller memory footprint, and composability in return.